Automatically load CSV files from Google Drive into BigQuery using AppScript
Automatically load CSV files into BQ with very little effort


UPDATE: December 4th, 2020: The code in the repo now supports Google Shared Drives, thanks to the moveTo() method replacing the addFile() method.
— —
I wanted to load CSV files into BigQuery as a way of doing some quick aggregation & automation, without the heavier lifting of pubsub/cloud functions/data flow etc. I wanted to do a first pass on a lower-priority project and also test it on some personal data to experiment within the free tier.
I guess if you want a non-scalable one-time way of doing this…
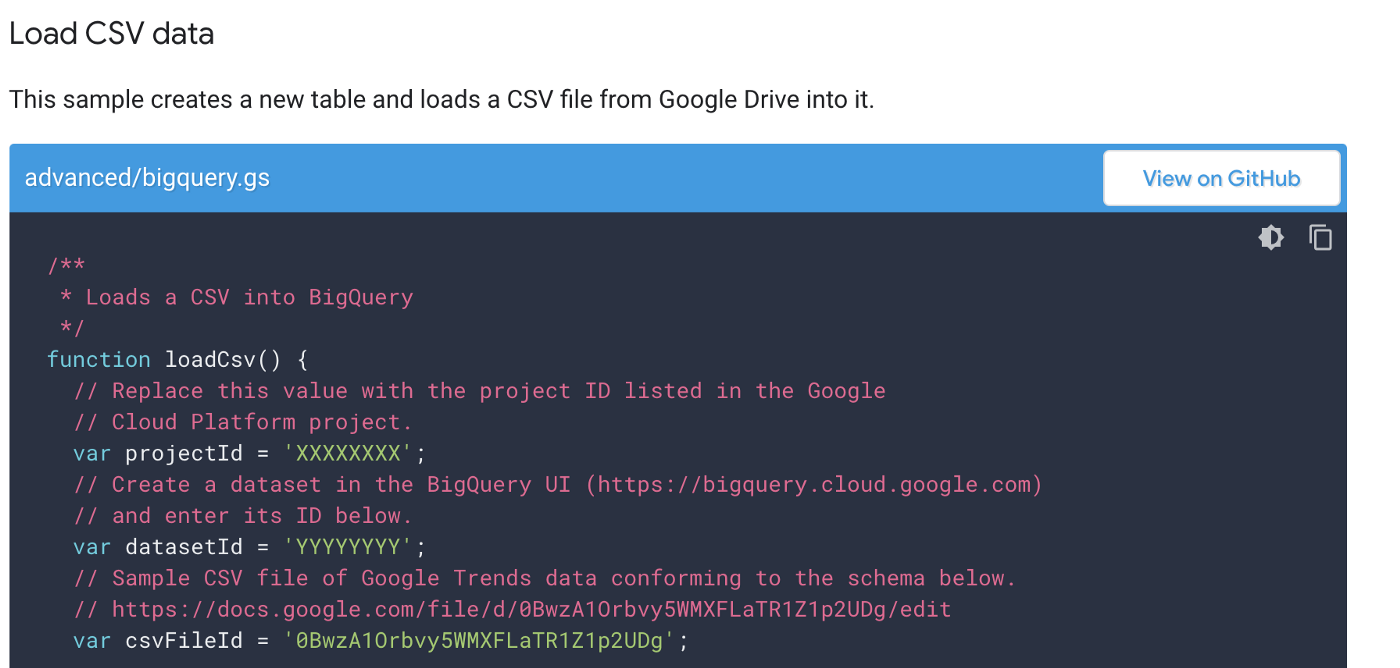
I could have followed Google’s documentation for a one-time CSV load approach: https://developers.google.com/apps-script/advanced/bigquery but….
Nah, let’s automate (a little)
I wanted to add a little automation to the process. I also wanted to handle multiple types of CSV files.
So…from a high level here’s what my approach does in AppScript (repo linked at the base of the article):
- Store different types of CSV files in Google Drive
- Use AppScript to create the target BQ tables for each type of file
- Use AppScript to periodically look at the folder, and load each CSV file into the appropriate target BQ table.
- Once loaded, the file moves into another directory (or can be trashed)
Some assumptions about the process…
- The CSVs are stored in Google Drive, not Google Shared Drives
(there’s a limitation on moving those files around as of right now if you want to use the built-in helpers for Drive in appscript). - This might not work for massive files, or things over a certain (unknown at this time) file size.
It might of course…not sure what the limits are on appscript and loading this way. - You will need to do some copy/paste code writing to change from what my repo code is, to what your CSV schema / BQ table names are.
Don’t worry, it’s pretty self-explanatory. - In future, you may need to update your appscript code and table functions if the CSVs change structure at any point.
More detailed details…
- Create a folder in Google Drive to store your CSV files that are pending processing, and then another to store processed CSV files.
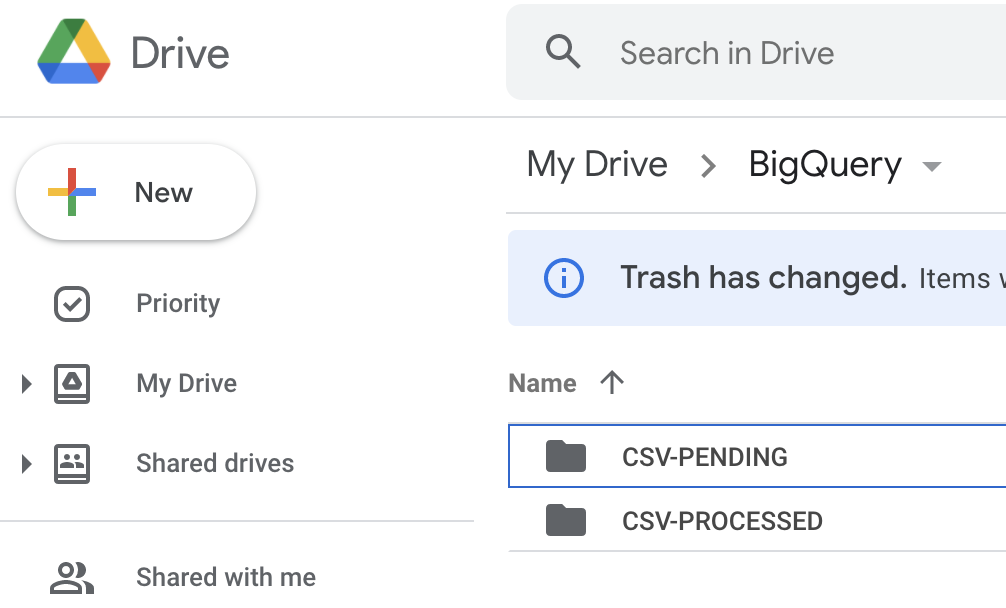
- Create a new project in google appscript (script.google.com)
- Copy the Code.gs file contents from the repo (linked below) into appscript, and then update the variables at the top.
- Update/write some functions to set up the tables you want. Follow the examples provided, ie: table_characters() and table_places().
- Just change what’s there, and copy/paste to create new table definitions based on what the CSV file(s) will contain.
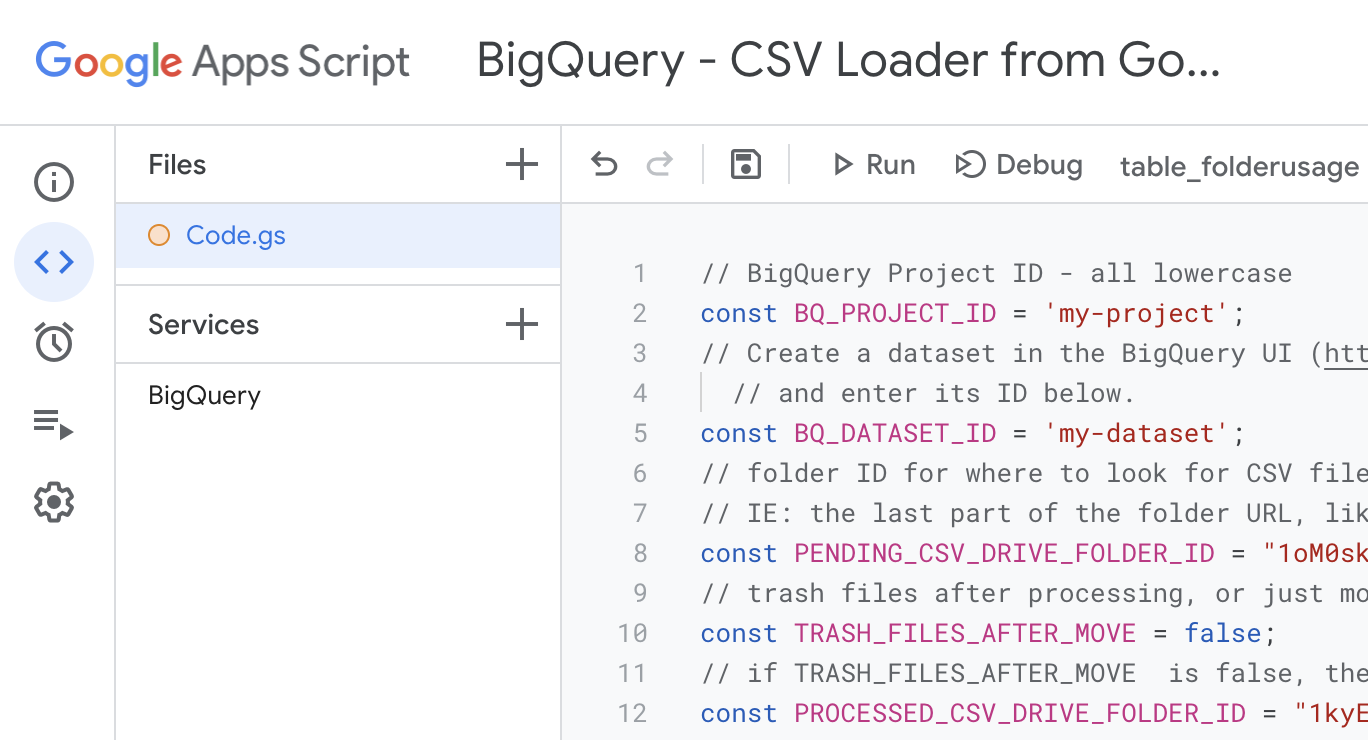
- Update the process_all_pending_csv_files() function’s switch/case statement, so that it knows what the first column heading is of each CSV file type. This is how the code parses the CSVs to determine which table function it should use for the BQ load job.
- Update the doCreateTables() function to point to the appropriate table functions.
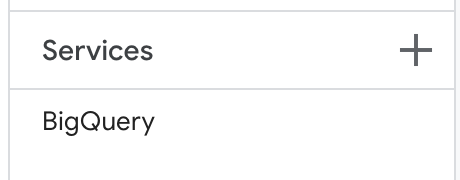
- Add the BigQuery Service to your project
(use option on the left-menu to add)
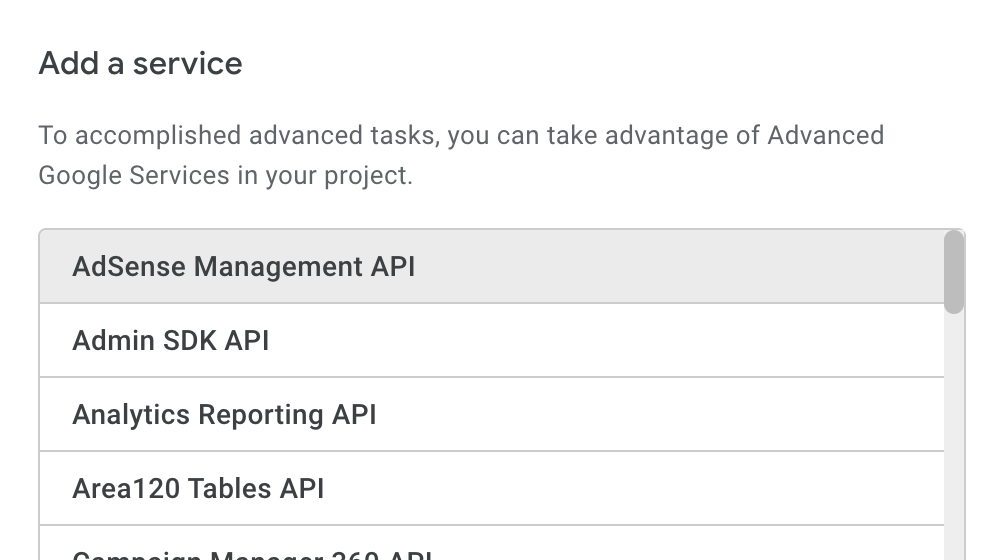
- Run the doCreateTables() function once, which will prompt for permissions, and then create your BQ tables
(if you did the above steps correctly). - Accept the permissions
(asking for access for your script to read/write to google drive, BigQuery etc) - Make sure there are some CSV files into the PENDING google drive folder you set up.
- Run the process_all_pending_csv_files() function
(once, or set a trigger to run on a schedule)

- Look in BigQuery at the jobs, and then the datasets and tables, and you should see data in your table(s) pretty quickly.
If you change the “id” in this URL….that’s where you should go to check it out: https://console.cloud.google.com/bigquery?project=id&page=jobs
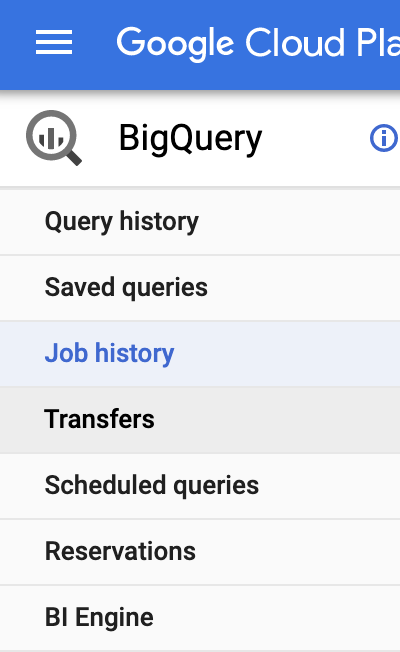
That’s pretty much it!
Hopefully, this was easy to follow and demystifies the process of getting some simple data into BigQuery without having to use a lot of tools, or complex workflows.
I know this process can be improved by autodetecting the schema from the CSV files to create the tables initially, and there should be some more error handling in there…but….that’s for a later commit and pull request :-)
Get the code…
Here’s the code: https://github.com/usaussie/appscript-bigquery-csv