Automate Multiple CSV to BigQuery Pipelines with Google Sheets & Apps Script
Want to load manage multiple pipelines of CSV files to different BigQuery projects/datasets/tables automatically, and control them all from a single Google Sheet?


Want to load manage multiple pipelines of CSV files to different BigQuery projects/datasets/tables automatically, and control them all from a single Google Sheet? Yes? Then this article is for you.
This process will even let you configure if you want the automation to truncate or append the data each time to the BigQuery table. Nice huh?
Background
A while ago, I wrote up a process for loading CSV files into BigQuery using Google Apps Script. That process used definitions in code for the types of CSV files detected, the load schema for BigQuery and a few other things. I realized for people getting started that was probably overkill and required them to write too much code for themselves. So, I rewrote the process to be a lot more simple, using a single Google Sheet to act as the pipeline manager.
Prerequisites
- Google Account
- Google Apps Script - script.google.com
- Google BigQuery Project(s), Dataset(s), Table(s) - console.cloud.google.com
- Copy of this Google Sheet
- CSV files(s) to load into BigQuery
- Code from this repository
Google Sheet & Drive Setup
First, Copy the Google Sheet into your own google account. Then create some Google Drive Folders to house your CSV files.
You will need one google drive "source" folder for each different type of CSV. YOu can have multiple "processed" folders if you'd like, or you can have the same "processed" folder if you want everything to end up in the same place. It's really up to you.
You will then update the Google Sheet with the Google Drive ID in the appropriate columns. The ID is at the end of the URL when using Google Drive in a browser. IE: if the Google Drive Folder URL is "https://drive.google.com/drive/u/0/folders/1-zFa8svUcirpXFJ2cUn31a" then the Drive Folder ID is "1-zFa8svUcirpXFJ2cUn31a" and that's what you'll put into the columns in the Google Sheet.
BigQuery Setup
You will need a BigQuery table per type of CSV that you want to load. IE: If you have 4 different kinds of CSV files, then you'll want 4 different tables. Those can be split across any number of BigQuery projects and datasets, but ultimately you'll need one table per CSV type.
If you already have BigQuery tables set up, then all you need to do is update the Google Sheet with the appropriate information (project ID, dataset ID, table ID)
If you need to create a new BigQuery table the easiest way, without writing ANY code, is to upload one of your CSVs via the bigquery console and use Autodetect to set the schema up for you. Then, each subsequent load of that type of CSV will be guaranteed to work.
Upload a CSV to Create BigQuery Table:
- https://console.cloud.google.com/bigquery
- Click the project name on the left navigation
- Click the 3 dot menu and create a new dataset
- Click on the data set name, and then click "Create Table"
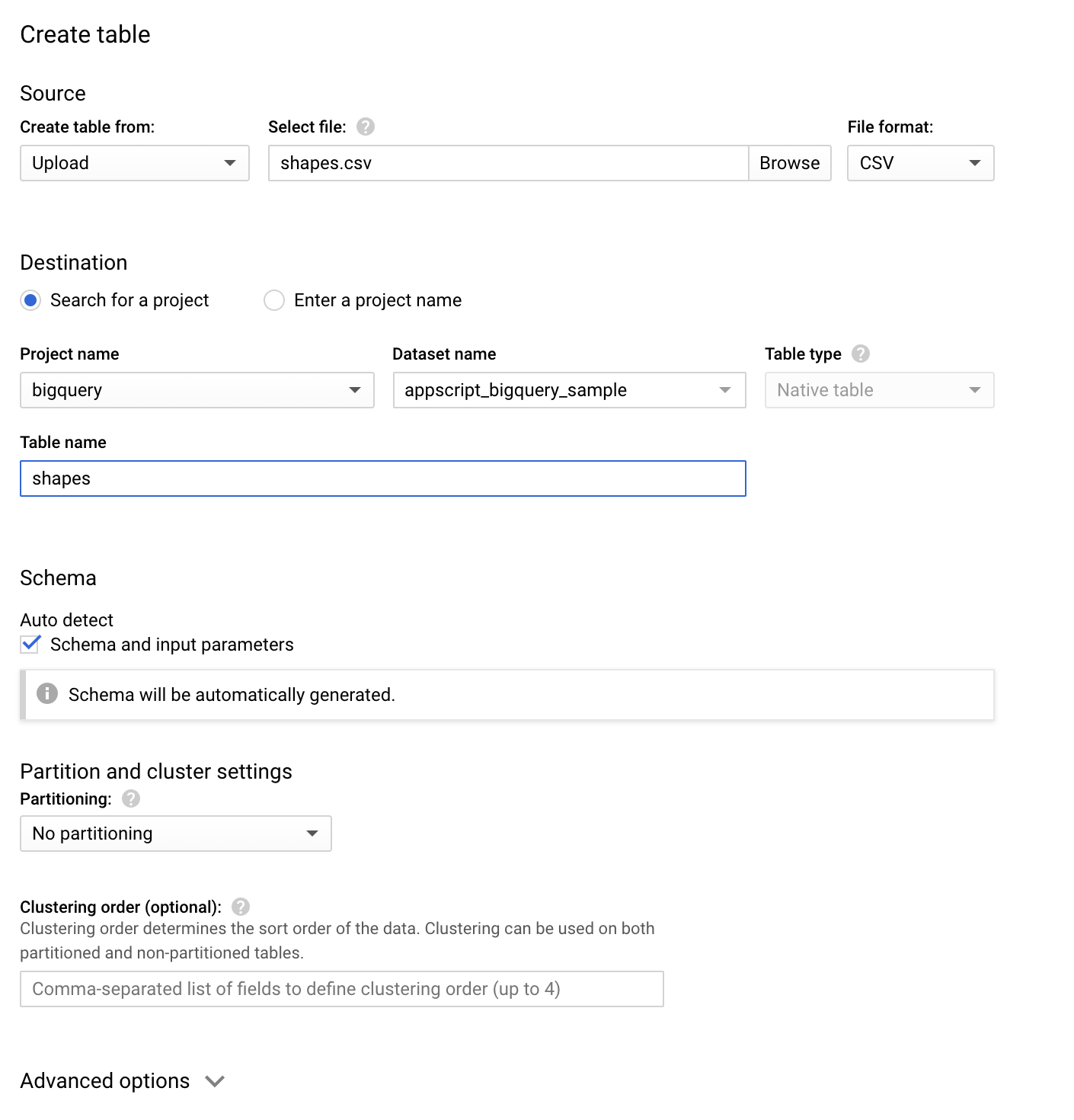
When your table is created, put the ID of it into the Google Sheet along with the project ID and data set ID.
Create your Apps Script Project and Configure the Code
By now you should have a Google Sheet with a lot of details filled in about your Google Drive Folder(s), your BigQuery Project/Dataset/Table(s), and now all thats left to do is put the code into place to make it all work together.
In the Google Sheet, open the Script Editor. At time of writing, ff you're using a personal gmail.com account, this will be via the Tools->Script Editor menu item. If you are using an organizational/school account, this will be via the Extensions->Apps Script menu item.
This will open the Apps Script Editor.
Copy the code.gs file contents from this github repository and paste it to replace everything in the existing Code.gs file.
Click the + icon to add a new HTML file, and name it "email" so your file list looks like this:
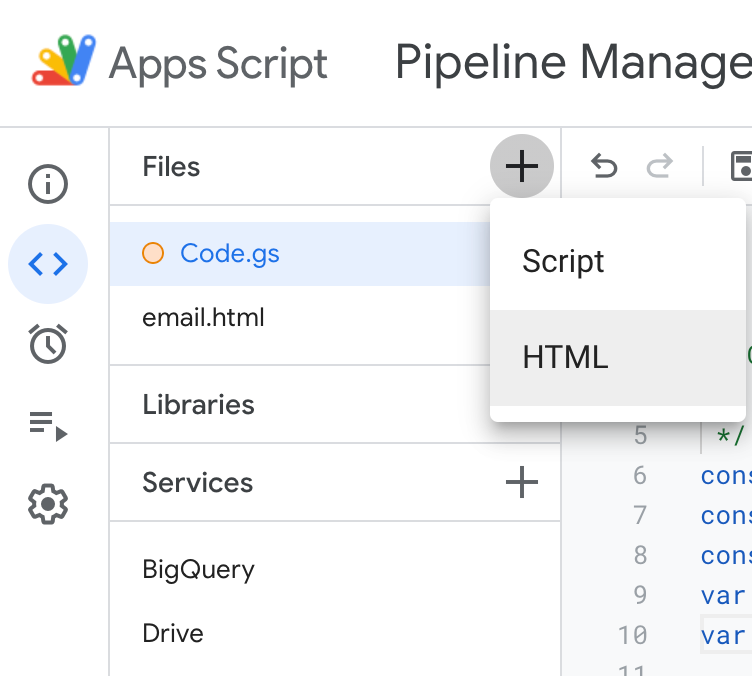
Copy the email.html file contents from the same github repository, and paste it into the email.html file in Apps Script.
Add the BigQuery and Drive service using the + icon beside the Services menu on the left (so your Services list looks like the screenshot above too).
Open the Code.gs file and update the variables at the top of the file. This is where you'll set things like the sheet tab names (if you've changed them from the original template) and the info that will go into the email notifications that this process can send too.

That's it. That's ALL the setup you need to do.
Let's make this thing run, shall we?
- Place a CSV of the appropriate type, into the Google Drive folder that is specified by your Google Sheet
- Inside Apps Script, click the run button at the top, and run the only function that's listed

- The first time you run this, Google is going to ask you if you're sure, in the form of a few security/approval prompts. This is normal...this is YOU granting access to YOUR Apps Script project to be able to use YOUR Google Drive, BigQuery and Gmail content/services. This is NOT allowing Google or anyone else to do things to your account. Just make sure you don't share the google sheet with other people who may use it for nefarious endeavors (because they can then also see and edit this code) .
- These prompts will look a little like this:
- After that...the script will run for the first time.
- Check the Google Sheet's log tab to see if it did anything.
- Now for fun, put a few more CSVs into the folder(s) and run the function again. See...it works!
- Next, you'll want to set up a trigger to run this function automatically on a schedule. Just use the Triggers menu on the left side of your Apps Script project to set the trigger up something like this:
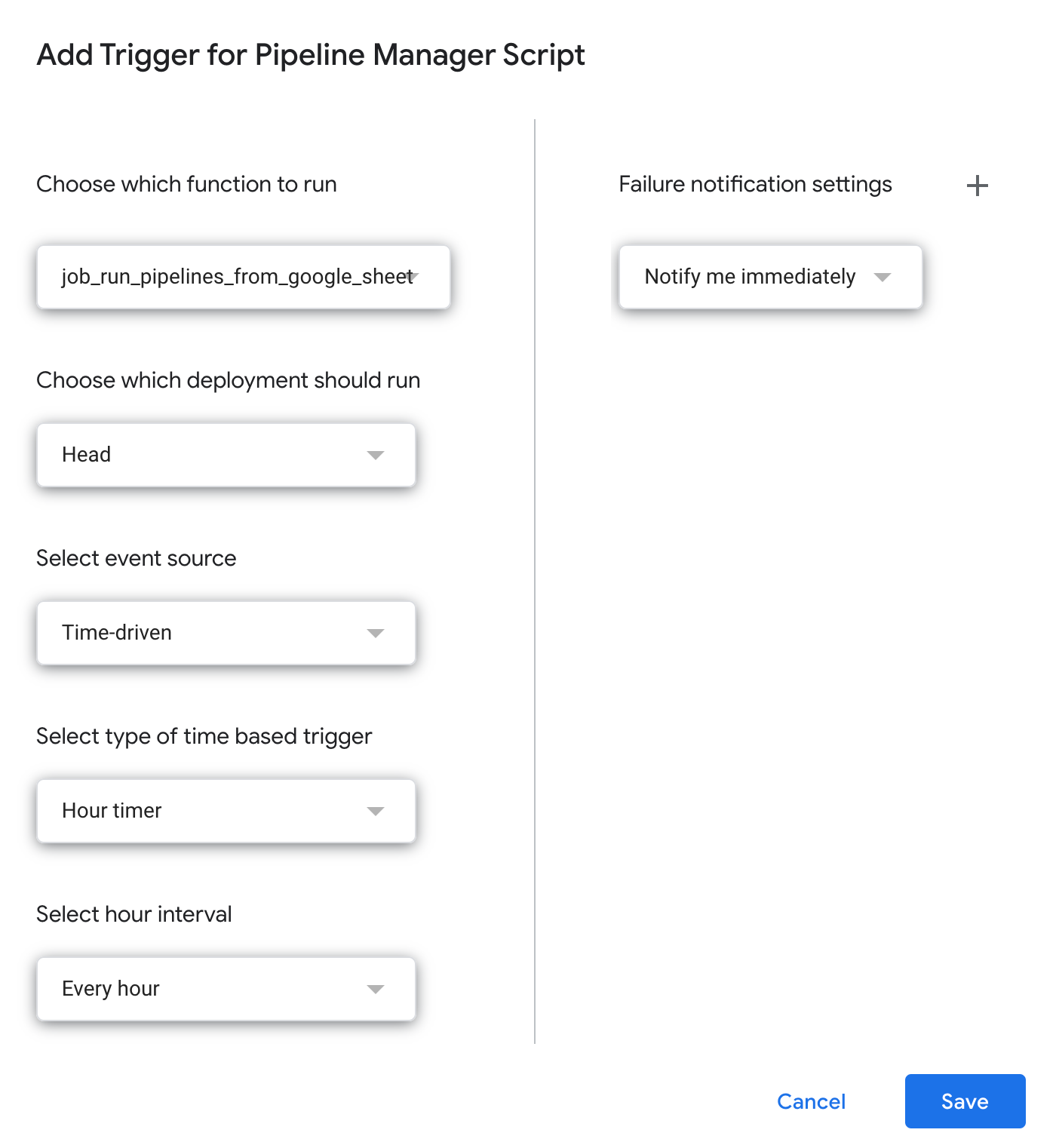
Now...that's really it. Simple, right?
You can see the results of the automated jobs in the BigQuery console – Look in BigQuery at the jobs, and then the datasets and tables, and you should see data in your table(s) pretty quickly. If you change the “id” in this URL….that’s where you should go to check it out: https://console.cloud.google.com/bigquery?project=id&page=jobs (this is in the google sheet logs as well).
Hooray!
Hopefully, this was even easier than the original article/approach to follow and demystifies the process of getting some simple data into BigQuery without having to use a lot of tools, or complex workflows.
 Nick Young
Nick Young
I know this process can be improved by autodetecting the schema from the CSV files to create the tables initially, and there should be some more error handling in there…but….that’s for a later commit and pull request :-)
Get the code…
Here’s the code: https://github.com/usaussie/appscript-multiple-bigquery-pipelines-google-sheet
 usaussie
usaussieThis article is probably posted on techupover.com and techupover.medium.com. You can also follow me on Twitter @techupover